


Revolution in machine vision and image analysis - Deep Learning
Aurora Vision Deep Learning™ software for Zebra Machine Vision camera systems uses a suite of advanced tools based on the so-called. Deep Learning to help improve the quality and operational efficiency of existing Machine Vision solutions. With use cases in a variety of industries, this software enables solutions to complex machine vision problems that were previously unattainable with traditional algorithms and approaches.
What is deep learning anyway?
Deep learning is a groundbreaking approach to image analysis and interpretation. Deep learning algorithms are designed to mimic how the human brain processes visual input, and perform this task with the speed and robustness of a computer system. Algorithms can be used to select patterns and identify key details from images or other visual information. This technology allows automated systems to accurately categorize objects, detect anomalies and defects, and perform complex tasks that were previously dependent on humans alone.



What are some examples of deep learning for machine vision?
- Deep learning object detection is used to locate and count objects or features in a complex and changing landscape. For example, deep learning-based object detection can be trained to perform assembly verification in a production environment, detectdetect and verify the presence and correct placement of components or parts at different stages of assembly to ensure correct installation.
- Deep learning image classification categorises images or regions of images to distinguish between similar looking objects, including those with subtleimperfections, facilitating tasks such as classifying objects based on visual characteristics or identifying specific components in manufacturing processes.
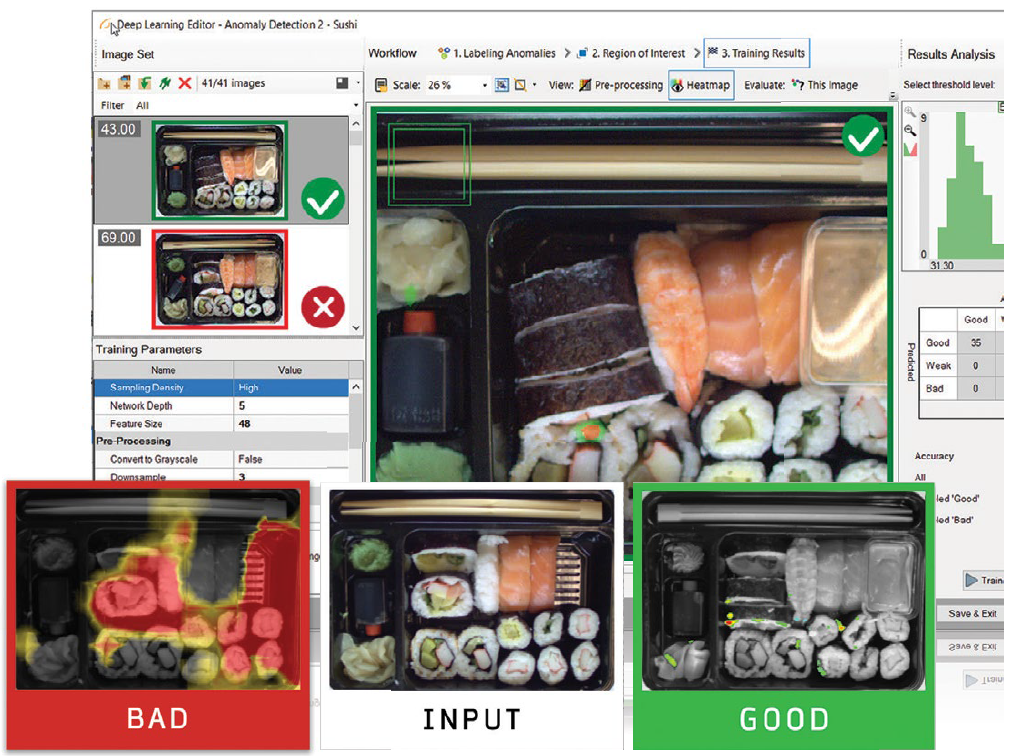
- Image segmentation involves dividing an image into multiple segments or regions based on certain criteria such as object boundaries or semantic content. Deep learning techniques allow for image classification at the pixel level, which enables the delineation of different regions or objects within an image. This capability is useful for tasks such as identifying and measuring the dimensions of components or detecting anomalies in complex machines.
- Deep learning has revolutionized OCR by enabling more accurate and robust text extraction from images. Deep learning models excel at recognizing and extracting text from images, enabling applications such as reading product labels, serial numbers or alphanumeric codes in industrial environments.


What is the role of deep learning in machine vision technology?
Deep learning is a key advancement in machine vision technology , particularly in the context of automated visual inspection. Deep learning for machine vision has revolutionized industries such as manufacturing, healthcare, and transportation by enabling advanced image recognition and analysis.
Deep learning models can be trained to recognize patterns, shapes or specific objects in images. Machine vision uses artificial intelligence (AI) and deep learning algorithms to analyze visualdata, feature extraction and decision making, taking advantage of the speed and reliability of computer systems. In the context of machine vision, deep learning excels at tasks such as image classification, object detection, segmentation, and OCR.
The result can be more flexible and user-friendly solutions that open up new opportunities for automation and intelligent manufacturing. Leveraging these deep learning capabilities can improve the industry by allowing systems to adapt and improve over time.
How does it all work?
At its core, deep learning mimics the neural networks of the human brain, which consist of interconnected layers of neurons. Deep learning models are built using multiple layers of neural networks, allowing them to process data in a complex way. "Depth" in deep learning refers to the number of layers through which data is transformed.
In the context of machine vision, convolutional neural networks (CNNs) are a fundamental architecture for tasks such as image classification, object detection, and segmentation. CNNs are also commonly used in optical character recognition (OCR) systems to extract text features from images, locate individual characters or regions of text.
At the core of CNNs are convolutional layers that perform feature extraction by applying filters to input images. These filters move over the input image and detect features such as edges, textures and shapes. As the image passes through successive convolutional layers, the network learns to detect increasingly complex patterns by combining and abstracting features from previous layers. After several convolutional and pooling layers, the resulting feature maps are merged and embedded into fully connected layers that perform classification or regression tasks based on the learned features.